P.1203 Extended: Our Ultimate Video Quality Measurement Model
In this blog post we would like to introduce ITU-T P.1203, a state-of-the-art video quality measurement model, and our improved variant, which we call P.1203 Extended. We will illustrate the improved aspects of P.1203 Extended, and how it compares to the core standard in terms of video codec support, resolution, accuracy and so on, and discuss why one might choose the upgraded version over the first one.
If you are a video streaming or web service provider, delivering the best possible quality content to your clients is likely essential to you. But how do you ensure that? You could conduct surveys regularly to assess their experience of your videos — measuring the Quality of Experience (QoE) by asking people — but that is neither very effective, nor cost-efficient.
Video Quality Models, a Short Recap
Video quality models are algorithms designed to do exactly that: automatically predict the quality a human would give to a video if they had to rate it. These models can evaluate how well a video meets certain standards of visual and audio quality. There are different types of computational models. Some compare a reference (original) video to a processed (distorted) video, while others evaluate a standalone video without reference. These models are classified as follows:
- Signal-based models: these vary depending on their access to original reference videos and can be full-reference, reduced reference, or no-reference models. They essentially work on the video pixels.
- Metadata-based models: these are no-reference models that use information about the video stream’s properties, such as resolution, codecs, bitrate, or framerate, and information about stalling.
- Bitstream-based models: these evaluate the video based on the data sent to the network in the form of video segments.
While full-reference signal-based models are the most accurate ones, they come with drawbacks in terms of applicability: in many cases, you cannot measure the pixels received at the end-user’s side. Also, if you are monitoring third party video services, you will not have access to the original reference stream to compare to. The same is true for live events.
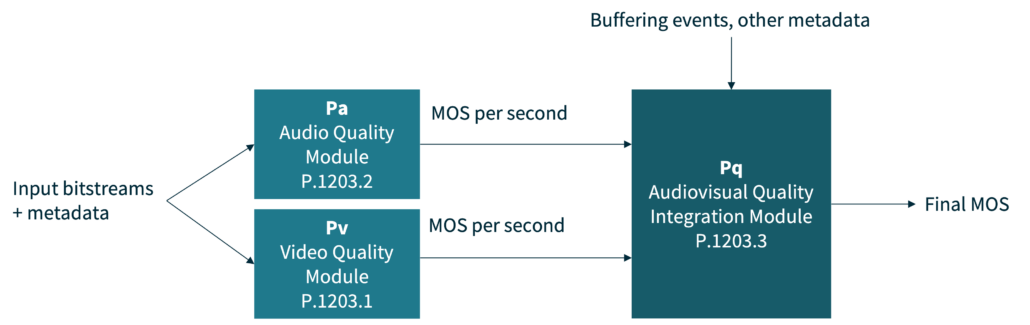
Metadata-based models are the best option in the aforementioned settings. They work purely from the client, while still being comparably accurate. Especially when your focus is on the question: “how well does this network work for video streaming?”, metadata-based models work very reliably. The “Mode 0” of ITU-T Rec. P.1203 is a prime example of such a model. P.1203 is actually an entire framework that combines video quality, audio quality, and delivery quality into a single score, the Video Mean Opinion Score (MOS).
Let’s dive into the details of P.1203 how we extended it — the focus of this post.
ITU-T P.1203 — The Starting Point
ITU-T P.1203, or simply P.1203, was initially developed in 2017 by members of the International Telecommunication Union. It was — and still is — the world’s first standardized HTTP Adaptive Streaming audiovisual quality model, designed to provide a method for evaluating the performance and QoE of video and audio streams. It defines a set of objective models, considering factors such as bit rate, resolution, and network conditions. It was trained on thousands of individual human ratings, with over a thousand test sequences that covered various quality degradations. The training and validation was done by multiple international academic and industrial partners, each ensuring that the entire process was rigorous and fair.
P.1203 differs from conventional, full-reference metrics (think SSIM, VMAF, …), as it can use both a metadata- and bitstream-based approach. This means there is no need for decoding or referencing the original source. It also works on sessions of up to five minutes length, compared to the typical video models that have only been trained on short sequences (e.g., 10 seconds).
P.1203 stands out for its relatively high accuracy for its use case, using three different modules to cover the audio, video, and temporal integration aspects of a streaming service. The latter are crucial for the final impression of a session — factors like quality fluctuations and stalling are considered here.
For the use case of holistic streaming session evaluation, P.1203 is the only published model extensively validated in academia, and we note more usage in the industry as well (we’ll share more about that soon!). Using P.1203 instead of relying on individual KPIs ensures a consistent and high-quality viewing experience for your end-users.
P.1203 Extended
AVEQ’s “P.1203 Extended” mode is the product of the joint efforts of AVEQ and ITU-T experts, aiming for an enhanced and more versatile model that caters for the needs of today’s streaming implementations. The extended version builds upon the original P.1203 standard, adding features to make it applicable in more scenarios relevant for current streaming environments. In a rapidly evolving technological world, the extended version includes, foremost, coefficients for new codecs that have appeared since the P.1203 standard was developed, and additional diagnostics to better understand the output of the model.
Let’s explore the key features — or rather, key differences — and additional capabilities of P.1203 Extended.
Video Codecs
While P.1203 as standardized only supports the H.264 video compression standard, P.1203 Extended also includes coefficients for the H.265/HEVC, VP9, and AV1 video codecs, facilitating practical measurements for services like YouTube or Netflix. We achieves this by deferring the video quality (Pv) calculation to the AVQBits|M0 model by TU Ilmenau. This novel model architecture is based on the P.1204 standard (more about this will follow in another post). You can read more about AVQBits in this open access scientific paper by Rakesh Rao Ramachandra Rao and his colleagues at TU Ilmenau. As with all these joint developments, AVQBits was based on the practical needs of the industry, but developed in a rigorous scientific process, ensuring the accuracy, validity, and reproducibility of the results.
Video Resolution
Video resolution is crucial in evaluating visual quality. When P.1203 was designed and created in 2014, 1080p was the de-facto standard. Higher resolution, however, often equates to higher perceived quality, and while 4K is still adopted rather slowly, you need to support the resolution in your quality measurements. Therefore, P.1203 with the TU Ilmenau AVQBits|M0 module supports video resolutions from 240p, 360p, 480p, 720p, up to 1080p and 2160p.
Video Frame Rates
Evaluating framerate is essential, especially in adaptive bitrate streaming scenarios. Higher framerates provide smoother motion and generally contribute to a more realistic perception of video content. While lower framerate renditions are less used nowadays, it’s still vital that QoE models handle degradations from reduced fps. P.1203 assesses and optimizes video frame rates up to 25 fps, while P.1203 Extended covers up to 60 fps, again due to its underlying AVQBits module handling these refresh rates.
Accuracy
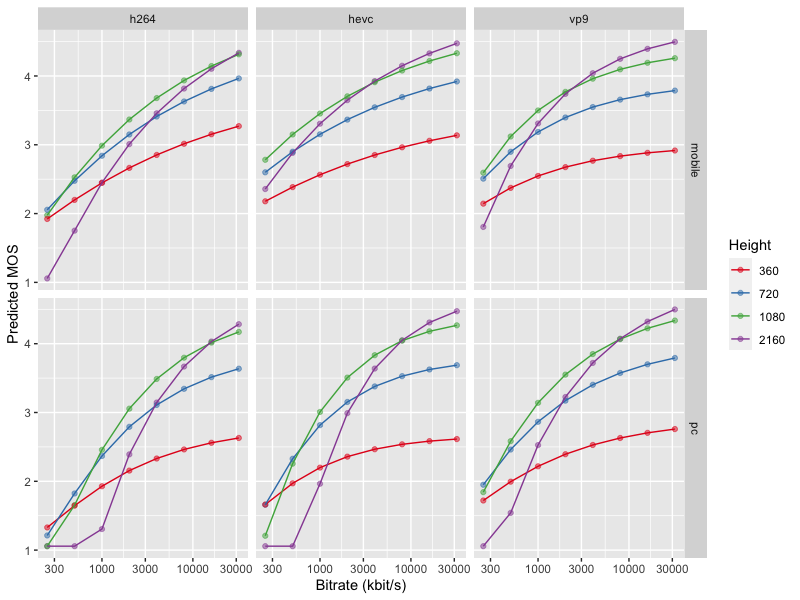
While P.1203 provides standardized high accuracy levels that have been tested and proven, P.1203 Extended is a better choice for users viewing videos over adaptive streaming. The original P.1203 standard could achieve an averaged Pearson correlation of 0.81 with the training and evaluation set. This includes test sequences with large quality variations of up to 5 minutes. The new AVQBits|M0 model performed with a correlation of 0.89 on the AVT-VQDB-UHD-1 video quality database, which covers short video sequences. In general, the new model works much better for combinations of low resolution and low bitrates such as found in today’s encoding bitrate ladders, as can be seen in this chart:
Diagnostics
P.1203 already excels in measuring various factors of an entire session:
- Audio quality per second
- Video quality per second
- Combined audiovisual quality per second
- Overall audiovisual quality (except stalling)
- Stalling quality (or rather, degradation)
- Overall audiovisual quality
These diagnostic values are part of the original standard. P.1203 Extended enhances this by offering a new diagnostic: the highest possible MOS, and additional derived stats such as a “Maximum theoretical MOS ratio,” which gives you a ratio between the achieved quality and the highest score that could have been reached if there had been no stalling, and no quality fluctuation. This is an essential score to consider for network monitoring, where the tested sequence remains the same over longer periods of time. Also, we added diagnostics like a 1-minute MOS, providing a more comprehensive assessment of video quality for videos of varying duration.
Session Length and Temporal Integration
In today’s streaming-focused world, service providers and OTTs value models that are as useful for longer videos as they are for short ones. In other words, your users are probably going to watch TikTok videos and stream 2-hour Netflix movies. (Maybe it’s not necessarily the same people, but they might use the same Internet connection at home to do that.) The standard P.1203 model performs measurements in 1 to 5-minute segments, and its validity beyond that time range has never been tested much. With P.1203 Extended, we also measure in “1 to 5 minutes”, but we can extend the overall score to a much longer period, using a sliding window-based moving average method. This flexibility is crucial for a better QoE assessment in adaptive streaming over longer broadcasts, or for movies.
Table: Comparison of P.1203 to P.1203 Extended
| ITU-T P.1203 | P.1203 Extended | |
|---|---|---|
| Video codecs | H.264 | H.264, H.265/HEVC, VP9, AV1 |
| Video resolution | 240p, 360p, 480p, 720p, 1080p | Up to 2160p |
| Video framerates | Up to 25 fps | Up to 60 fps |
| Accuracy | Standardized and proven accuracy | Higher accuracy for testing adaptive streaming bitrate ladders |
| Diagnostics | Audio quality per-second Video quality per-second Audiovisual quality per-second Stalling quality Overall audiovisual quality | All of the default ones, plus: Theoretical maximum MOS Max. MOS Ratio Overall audiovisual quality without stalling 1-minute MOS |
| Time range | 1–5 minutes | 1–5 minutes Longer video: Sliding-window-based moving average |
By integrating these diverse parameters, the P.1203 Extended ensures a reliable view of the QoE. Additionally, it provides diagnostic information, enabling you to easily detect issues with your service.
Why Choose P.1203 Extended?
The current ITU-T P.1203 standard is fully reproducible by implementing the standards document(s) from ITU-T itself. There is also a reference software available, which has been used a lot in academia. However, as you can see from the above article, the standard lacks coverage for other codecs and higher resolutions/frame rates. Furthermore, in practical deployments, you may need more diagnostics. Finally, commercial licensing options must be available. With our extended version, we got you covered on all of these aspects.
We not only developed the original reference source code; we also have implementations of the standard available in different programming languages, or access via an easy-to-use server endpoint. And of course, the models are built into our prime solution, Surfmeter, where you can easily get your measurement results for various streaming services (including yours, if you run one!) through a customizable dashboard or API.
AVEQ P.1203 Extended is a more advanced and comprehensive model for predicting and monitoring QoE in adaptive streaming services. Its improvements in accuracy, diagnostics, and technology, including new codecs, make it a superior choice for service providers aiming to deliver the best possible streaming experience to their users.
Those who deploy our model will of course receive consultation for service-specific adaptations from no one less than the co-inventors of P.1203. Our experts will keep you up-to-date with standards-related developments and extensions, and you can save time and effort by getting your implementation directly from AVEQ. For any questions, feel free to get in touch with us.

