Video Quality Models and Measurements — An Overview
You’re probably here because you have worked with video in one way or another. Maybe you are creating video and encode it for later distribution, or maybe you operate a network that handles video — and in that case, probably a lot of it. The quality of videos is one of the most important factors that determines the overall user experience (and the Quality of Experience, QoE) of a video-based application or service. So it’s only natural that you want to measure and optimize the quality of your videos. In this blog post, we will discuss the different ways to measure video quality — both objectively and subjectively — and how to use these measurements to optimize the quality of your videos.
Video Quality — What does Quality even mean?
What is “quality”, even? There are various definitions, some related to the notion of “qualitas”, or inherent characteristics, of a thing. In the context of QoE, we should rather understand “quality” in the sense of “an individual’s comparison and judgment process.” This is how the QUALINET White Paper on Definitions of Quality of Experience defines it. That definition of quality includes someone perceiving and reflecting about that perception, and the description of the outcome. Basically: watching something and giving it a thumbs up or thumbs down. Which is probably what your users are doing.
When streaming video, quality is often felt by the lack thereof. Sure, many people get excited by high-resolution streams and multi-channel audio experiences in a positive way, but it is often defects in quality that lead to a negative experience. These issues can range from artifacts in the video stream itself (e.g., due to bad encoding settings) to buffering during playout (e.g., from a bad Internet connection). And we know that such experiences lead to frustration and, in the worst case, to the user abandoning the service. In their 2013 paper, Krishnan et al. already showed that even small increases in video startup time can lead to a significant drop in user engagement. We can only assume that this is even more important today, with the rise of streaming services, the increasing competition in the market, and growing user expectations.
So, by measuring the quality, we can understand where the problems are, and improve the experience for the end-user.
How do we measure Video Quality?
As we have seen before, we can loosely group video quality issues in two categories:
- those that are inherent to the video itself, and
- those that are caused by the delivery of the video.
The former can be anything from low resolution to compression artifacts, while the latter can be resolution switching or buffering (due to network congestion or incorrect player configuration), or even failures of the device used to play the video.
The overall Quality of Experience is, among other factors, determined by a combination of both the video quality and the delivery quality. This is why it is important to measure both of these aspects to get a complete picture of the user experience. Sure, there are other factors like the mood of the user, the context in which the media is consumed, or the expectations of the customers (in relation to what might be paying), but these are hard to measure and quantify in a practical setting. So we focus on the measurable aspects of quality now.
To actually get a measure of quality, that is, some number we can operationalize, we can rely on two principal methods: subjective and objective quality assessment. Subjective quality assessment is the most direct way to measure the quality of a video. It usually involves showing the video to a group of people and asking them to rate the quality of the video. This can be done in a controlled environment, like a lab, or in the wild, where the video is shown to real users. The latter is often referred to as crowdsourcing. Objective quality assessment, on the other hand — well, we should not really call it “objective”, but we will get to that later — uses algorithms to measure the quality of a video. These algorithms analyze the video and calculate a quality score based on the characteristics of the video. The advantage of this type of quality assessment is that it is faster and cheaper than subjective quality assessment. However, it is not always as accurate as subjective quality assessment, because these algorithms have to make compromises and assumptions.
The following image shows how the usual algorithm development works:
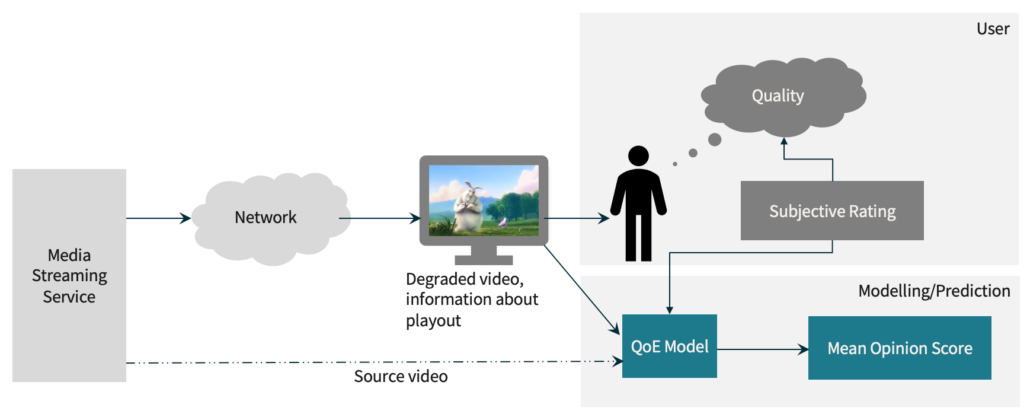
We have a (simulated) streaming service, playing artificially degraded videos, which users watch. We then ask the users for a rating of the quality, and use that to train a model. That rating is an encoded version of what they actually experienced, so there are always some biases in how the rating procedure itself is designed, but we’ll save that for another post. The QoE model then might predict a Mean Opinion Score based on the ground truth subjective data and whatever information it has access to. This could be the video itself, metadata, or bitstream data, and we will get into that later.
Since these so-called objective methods have been trained on subjective data, they are, for the most part, inherently biased and, in a way, subjective too. The term “instrumental” would be preferred, here. The fact that there can only be so much training data means that a resulting model is only valid for a particular scope in which it has been developed, and may not be directly applicable for other scopes. In the end, we should always validate the results of objective quality assessment with subjective quality assessment to understand how well a given model works.
Above, we introduced the term “model”. A model is a mathematical representation of a system. In the context of video quality assessment, a model is a representation of how humans perceive video, and it usually outputs a video quality or QoE score. These models are used to predict the quality based on the characteristics of the video or a stream. There are many different models out there, each with its own strengths and weaknesses. Some models are better at predicting the quality of videos with compression artifacts, while others are better at estimating the overall quality of delivery of a video, that is, they only or primarily look at buffering degradations and quality fluctuations. The choice of model therefore depends on the use case and practical considerations.
And what is a “metric”, then? A model may produce one or more metrics, and a metric has specific properties, like being on a known scale, and being interpretable. The Mean Opinion Score, or MOS, is a metric that is often used in subjective quality assessment to gather ratings from humans. It is a score that ranges from 1 to 5, where 1 is the worst possible quality, and 5 is the best possible quality. In objective quality assessment, we also often use metrics: these metrics are also on a known scale, and can be interpreted in a meaningful way. In fact, many models produce a MOS as their primary output metric. (Don’t be confused: MOS can be used for both subjective and objective measurement results.)
In the remainder of this post, we’re not going to go into details about subjective testing and subjective MOS values, as that is a very complex matter of its own. Instead, we will focus on objective quality assessment, and the models that are used to predict the quality of videos.
General Classification of Video Quality Models
When we want to understand how different models work, we should first classify them. There are the following categories:
- What the models focus on: video quality, or delivery quality, or overall quality (of experience)
- Whether the models have access to an original reference video or not
- Whether the models use metadata, bitstream data or decoded video data (pixels), or a combination thereof (hybrid models)
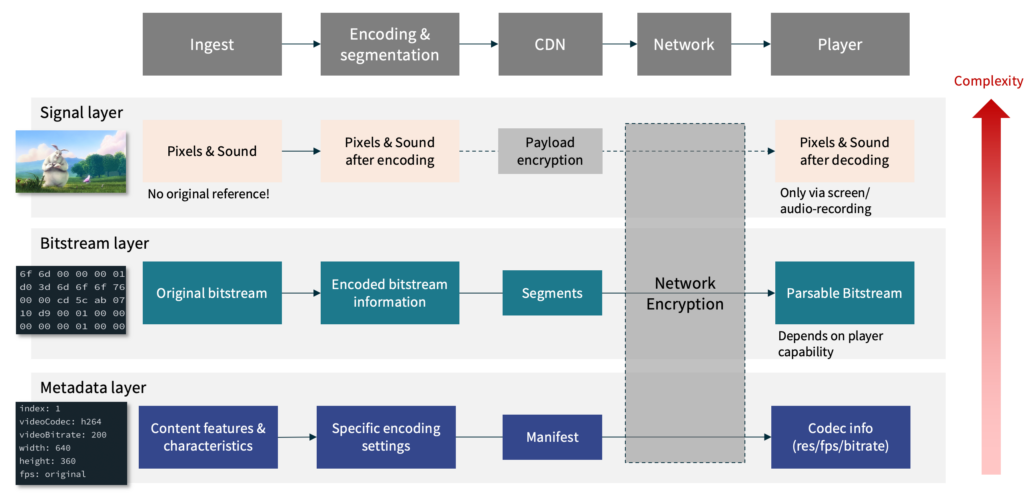
We’ve already established what the models focus on. Typically you will see a focus on video quality itself. The second and third category, the kind of input the models use, are important because these determine how the models can be used in practice. To understand the background, it helps to look at a diagram that shows a typical transmission chain for video streaming.
From the left to the right, we have the areas of:
- Ingest
- Encoding and Segmentation
- CDN
- Network (i.e. Internet transmission)
- Player
The three rows are model types based on the input data they use — signal, bitstream, or metadata. The individual blocks tell us which information is available at which stage. You can already see that the actual network transmission typically involves encryption, with packaging/CDNs sometimes adding payload encryption in the form of DRM. This limits the availability of some of the data. The player, on the other hand, has access to all the data, but it is also the most complex part of the chain, and the most difficult to analyze from a pure engineering perspective.
Let us now focus on the signal-based models first, and then move on to bitstream-based and metadata-based models. A caveat: this section will never be complete — whenever we give examples, we aim for providing references to standardized models, open-source ones, or de-facto standards that have been well-validated.
Full Reference Models for Video Quality
We begin with full reference models. Full reference models compare the received, or encoded video to a reference video, which is assumed to be of perfect quality. These models look at the actual pixels, frame by frame, and compare them to the reference video. Generally, these models are the most accurate, but they are also the most computationally expensive because they require decoding and involve lots of signal processing. Examples of full reference models are PSNR, SSIM — which have been around for quite some time now — and VMAF.
The following image shows how full reference models operate, and what data they compare:
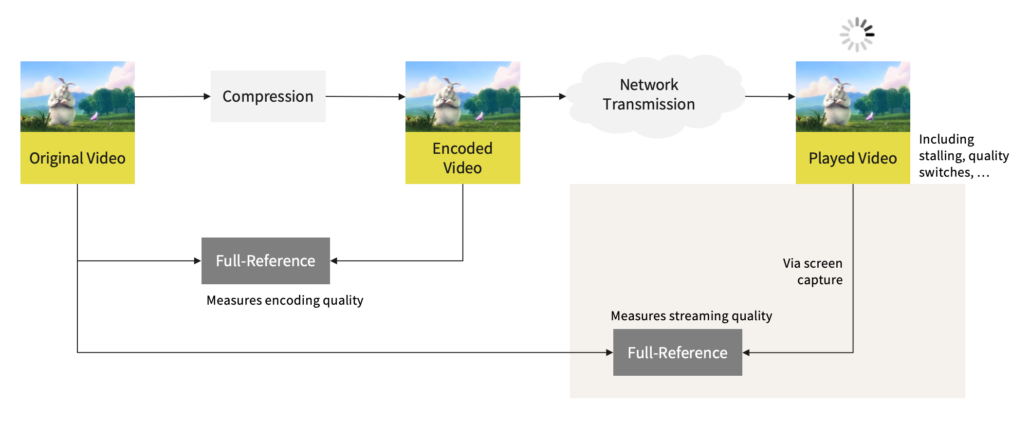
In fact, you can see two distinct applications: checking encoding quality, and checking the entire network transmission. The latter is a more complex use case because you have to work with screen recordings, which limits the use in DRM contexts, and it also means you have to time-align the videos and detect stalling. This is why full reference models are rarely used for an entire delivery chain, but rather for checking (and improving) the quality of the encoded video before they are transmitted.
To better understand how these full reference models work, let’s start with PSNR. The Peak Signal-to-Noise Ratio (PSNR) is a simple and widely used metric to measure the quality of a video. It compares the original video to the received video and calculates the difference between the two. That difference is based on the mean squared error, that is, the error between the same pixels in the reference and distorted video. The overall PSNR is then expressed in decibels, which is on a logarithmic scale. The higher the PSNR value, the better the quality of the video.
However, PSNR has some limitations. It does not take into account the human visual system, and it is not well-correlated with human perception. In fact, you can easily create images that look great but have a poor PSNR, and vice-versa. There are variations of PSNR that should provide better results, but they are rarely used (PSNR-HVS, and PSNR-HVS-M).
An improved full reference metric is SSIM. SSIM stands for Structural Similarity Index Metric, and it is a more advanced metric that takes into account human visual perception. It compares the luminance, contrast, and structure of the original video to the received video. The SSIM value also has a more understandable range from -1 to 1, where 1 is the best possible correlation between the two images. SSIM has become quite famous because it’s easy to compute and correlates better with human perception than previously developed metrics. However, it also has its limitations, especially when it comes to video.
You might have noticed that I talked about images now … weren’t we talking about videos? Yes, we were. PSNR and SSIM are metrics that were originally developed for images. People have used them for videos, basically calculating the metrics frame by frame, and then averaging them over the entire video. So, in the end, you get a single score that represents the quality of the video. That is a very basic assumption that works well for many use cases, but not all. For example, if you have a video with a lot of motion, PSNR and SSIM might not be the best choice, because they don’t take into account the temporal aspect of the video, and how adjacent frames differ. In that case, we need metrics that incorporate temporal information. Also, PSNR and SSIM were trained mostly on datasets with artificially introduced distortions like gaussian blur, salt and pepper noise, etc. These are not representative of what users typically consume online, where most artifacts stem from lossy compression with codecs like H.264.
Where image-based metrics are not enough, VMAF comes in. Video Multimethod Assessment Fusion is a more complex model developed by Netflix that uses machine learning to predict the quality of a video. It was trained on a reasonably large dataset of subjective quality scores from existing datasets, and new datasets created by Netflix. We don’t know exactly which video datasets were used, but we can assume that these were representative of what Netflix does in their internal processing, so there was a lot of focus on compression and video scaling artifacts, that is, choosing different encoders, reducing the bitrate, and lowering the resolution. VMAF makes use of individual features to predict the quality. The features include VIF, an image-based quality metric, ADM (or DLM), a detail loss metric, and a motion-based feature that calculates the difference between adjacent frames. These features are calculated frame-by-frame, and then combined using Support Vector Machines (SVM). The output of VMAF is a quality score that ranges from 0 to 100, where 100 is the best possible quality. Recently, VMAF has also added support for a banding metric called CAMBI, which is useful for videos with a lot of gradients, like skies or walls.
VMAF has been established as the de-facto standard for video quality assessment in the industry. It is used by many companies to measure the quality of their videos, and it is also used in research to compare different models. VMAF is also open source, which means you can use it in your own projects. The code is available on GitHub — and a wrapper for FFmpeg exists, too.
That said, there are also other full reference models that are perhaps not that widely known. ITU-T has standardized some, in their recommendations ITU-T J.144 (which includes CVQM, an old but quite reliable metric), J.247, and J.341. Commercial implementations of those standards may exist by different vendors. There are other FR metrics, mostly commercial, but few of them have been publicly validated, so it’s hard to say how well they work. There’s also FUNQUE+ which works on HDR video and claims higher performance than VMAF.
To summarize, if you have a reference video available, full reference models are the way to go. They are the most accurate and can give you a good idea of the quality of your videos. However, they are also the most computationally expensive, so you should be prepared to spend some time processing them. Some tools to help you get started with full reference models are FFmpeg, which can calculate PSNR and SSIM, and the VMAF repository, which contains the code to calculate VMAF. FFmpeg can also calculate VMAF, but the setup is more involved. Werner, CEO and co-founder of AVEQ, wrote a free, open source wrapper that handles the command line for you, so you can get started with FFmpeg-based quality metrics quickly.
Reduced Reference Models for Video Quality
Reduced reference models use a subset of the data to make their predictions: they can use features of the reference video, and use those features to compute the difference between the original and the received video. This means the features can be sent over the network from a server to a measurement device, requiring little bandwidth contrasted with sending the actual videos themselves. Reduced reference models may be less accurate than full reference models, but not always! In general they are less computationally expensive than full reference models. One recent example of a reduced reference model is ITU-T Rec. P.1204.4, which has outperformed full reference models in the same test conditions.
There are few practical tools available to calculate reduced reference models, as they are often proprietary. One is ST-RRED, and you can find a MATLAB implementation in the VMAF repository.
No Reference Video Quality Models
No reference models do not use any reference at all. When working with pixels, they try to detect encoding artifacts or other impairments in the video. Some of them also attempt to detect quality issues from the content itself.
These models are, generally speaking, the least accurate. But they are, compared to full and reduced reference models, also usually the fastest to compute. And in some cases, where there is no reference available, they are the only option you have to obtain quality scores.
The reason these pixel-based no reference models are less accurate is that they have to make assumptions about the video, and these assumptions are not always correct. Consider the use case of user-generated video content: these videos will be processed by users on their phones, and uploaded to a video platform. As a platform provider, how do you know what the original quality of the video was? The video may be bad because the camera itself was dirty, or because the user applied a fancy filter that tripped the model. Or the lighting conditions were such that the video could never be good at all. Some artistic intents cannot be captured by such models either.
This is why no reference models are not widely deployed, at least for predicting overall quality. There are some commercial solutions available, but they are not independently validated in terms of performance, so again, it’s hard to mention them here.
What you can use no reference analyses for is checking individual artifacts. For example, you can use a no reference metric to test a video for things like:
- blockiness
- blurriness
- black frames
- color space issues
- jerkiness
- flicker
These are individual features that can be more easily computed even in the absence of a reference. These types of indicators can be used, for example, in ingest pipelines to detect and flag issues, or after encoding, to check the quality of the encoded video. For user-generated content these could at least highlight possible issues with videos that can be relayed back to the user.
Various no reference indicators are made available by AGH University — but note that these cannot be used commercially. Also, there is a MATLAB implementation of NR metrics created by the NTIA, creating an overall metric called Sawatch. Make sure to read the extensive documentation! Some no reference models like Google’s UVQ incorporate deep learning techniques to understand the impact of content on the overall quality, and they output multiple metrics, as well as an overall score. nofu from Steve Göring’s pixel models collection uses machine learning-based features to generate an overall quality score, too.
Bitstream-based and Metadata-based Video Quality Models
The previous models we’ve shown operate based on the signal layer, but there are other types of no reference models that can either be used in many more situations, or get much more accurate. To understand the hierarchy of data these types of no reference models use, let’s look at the following diagram:
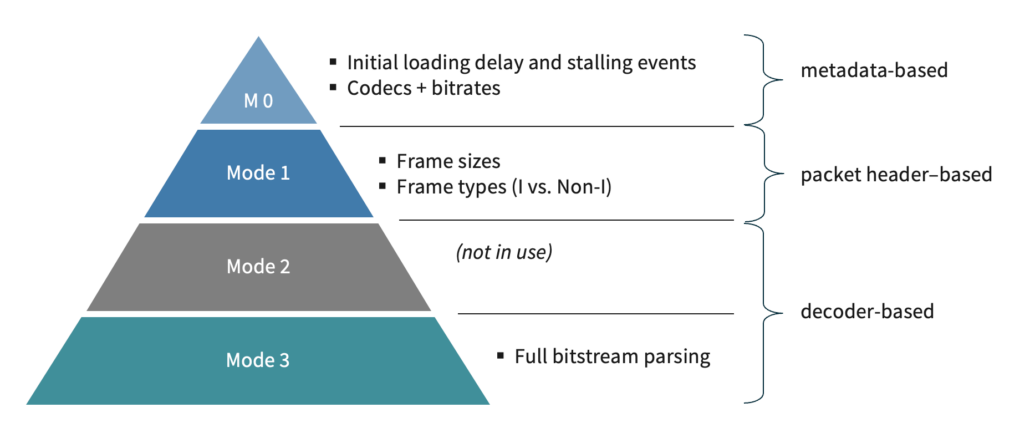
These four modes are from the ITU-T P.1203 recommendation. Mode 0 is the most basic, and uses metadata only. Mode 1 uses frame sizes and types (e.g., which you would get from DRM-protected streams), and Mode 3 uses the bitstream data. Mode 2 originally measured only a small amount of the bitstream but was later discarded because it was impractical to implement. The general idea is that the more data you have, the more accurate the model can be, but the more complex it is to deploy.
So, from the above, we now see that metadata-based models are, in some way, no reference models as well. They can use metadata from a player or other side-data that inform about the properties of the video stream. Metadata includes information about:
- resolution
- bitrate
- framerate
- codecs used
Here, we often find use cases where delivery quality is more important than video quality. Metadata cannot inform about issues with video encoding itself, as no pixels are available. But when combined with detailed data from a player, we know more about rebuffering events, quality switching, and the general quality of an entire session. A famous example of a metadata-based model is ITU-T Rec. P.1203, which is actually a framework that combines video quality, audio quality, and delivery quality into a single score. P.1203 has a reference implementation and has been successfully used and validated in many research projects.
The main benefit of the P.1203 model is that it can predict the quality of a video based on metadata alone, which can be very useful in practice, and that it factors in both video and delivery quality, which is important for the overall QoE. Most other models cannot provide session-based quality scores, but only per-segment or per-video scores. Here, P.1203 is unique. P.1203’s video component obviously cannot inspect the actual video stream, so it cannot be used to detect faulty encodes, or specific compression artifacts (you want to use no reference models for that). But this is also not the use case for which it would be deployed; instead, the delivery quality is in focus. When we evaluate the performance that a network can provide, we can use P.1203 to predict the quality of videos that will be played out over that network. This is useful for ISPs, who can then optimize their networks for video delivery, and who can assume that the content they stream is free of defects.
The default video quality component of P.1203 is a little bit outdated, covering only H.264 video up to 1080p resolution. But it is replaceable, and our academic partner TU Ilmenau has developed an update for that component to make P.1203 cover new application areas, like 4K, 60 fps video, and codecs like HEVC, VP9, and AV1. This new model is called AVQBits, and it is described in this paper.
Last but not least, in the above diagram, bitstream-based models evaluate the video based on the bitstream itself, that is, the data that is sent over the network in the form of video segments. These models can be very accurate, but they require access to the bitstream, which is not always available due to network encryption or DRM. But in cases where the bitstream is available, these models can be very useful. They can be used to predict the quality of a video without having to decode it, which can save a lot of time and resources.
Models like ITU-T Rec. P.1204.3 can be as accurate as full reference models, in some cases, as TU Ilmenau has shown in this technical report and this publication. There is a reference implementation available, too. Since there is no commercial entity behind the model, it has, so far, not been widely deployed outside of academia. Its predecessor, the P.1203.1 Mode 3 model, has also successfully used bitstream data to predict video quality.
Putting it all together: How users perceive video quality
The plethora of models and use cases make for a seemingly complex landscape of video quality assessment. But in the end, it all boils down to the same thing: understanding how users perceive video quality, and how to optimize the quality of videos for the best possible user experience. The choice of model depends on the use case, the availability of data, and the computational resources required. Full reference models are generally the most accurate but also the most computationally expensive, while no reference models are often the least accurate, but the only option available. Metadata-based and bitstream-based models fall somewhere in between, offering a good balance between accuracy and speed.
The use cases are manifold, as you can see from the diagram below:
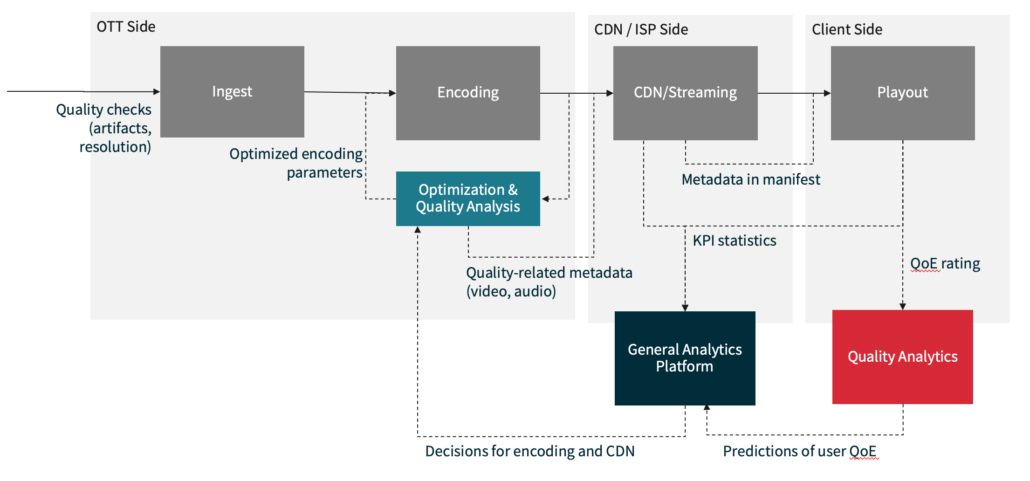
Whether you are checking ingest quality, your encoding pipeline, the CDN performance, the network quality, or the player performance, there is a model (or a combination thereof) that fits your needs. With each solution comes a different set of requirements and tradeoffs, and a different set of benefits. By carefully selecting and applying these models, you can significantly improve the quality of your video offerings, ensuring that viewers receive the best possible experience. Lastly, let us consider that there is no single MOS value, and you also cannot compare MOS values created by different models.
Measuring Video Quality is essential in order to enhance it
To conclude, measuring and enhancing video quality is essential for improving user experience and satisfaction in the area of video streaming and distribution. Our post has explored various methods for assessing video quality, from subjective evaluations based on human perceptions to objective assessments using algorithmic calculations. Each method offers unique insights into the quality of video content, whether it focuses on inherent video characteristics, or issues related to the transmission process.
Objective and subjective assessments each have their strengths and limitations. While subjective methods directly gauge human reactions to video quality, they can be influenced by individual differences and context. Objective methods, using algorithms to generate quality scores, offer a more consistent approach but must be carefully calibrated and validated against human judgment to ensure their effectiveness. When deploying these models, it is important to consider the specific use case and the availability of data, as well as the computational resources required for each method.
We also discussed several models for predicting video quality, including full reference, reduced reference, and no reference models, and how they work. Additionally, the integration of metadata and bitstream data into modern assessment models enables a deeper understanding of delivery-related quality issues. Such advancements are particularly useful for optimizing network performance and enhancing the overall Quality of Experience.
At AVEQ, we can help you navigate the complexities of video quality assessment and optimization, providing expert guidance and solutions tailored to your needs. Contact us today to learn more about our services and how we can help you enhance video quality for your audience.